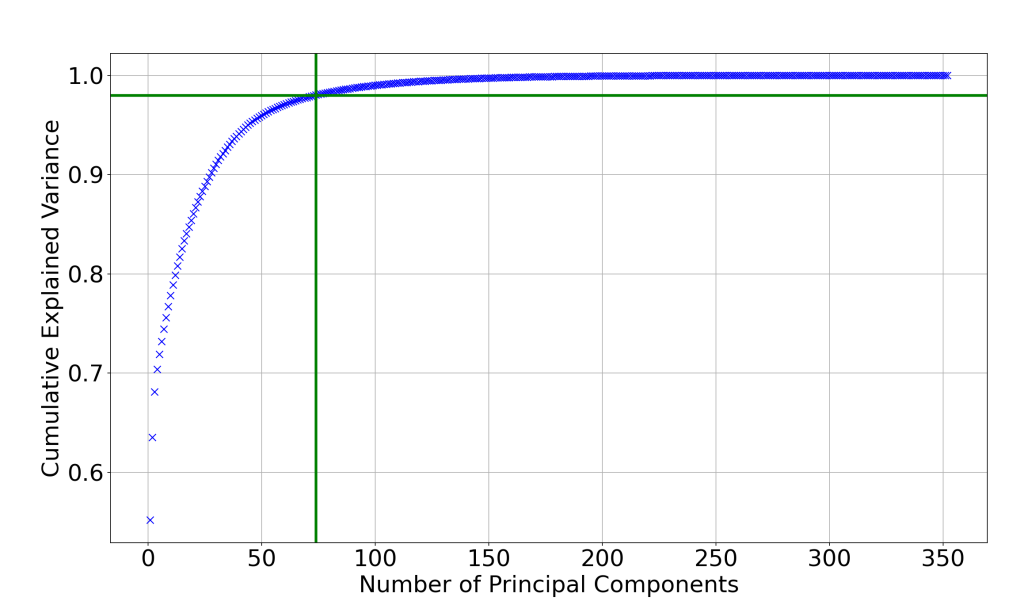
mean wt CN_1, std_dev wt CN_1, minimum wt CN_1, maximum wt CN_1, mean sgl_bd CN_1, std_dev sgl_bd CN_1, minimum sgl_bd CN_1, maximum sgl_bd CN_1
mean wt CN_2, std_dev wt CN_2, minimum wt CN_2, maximum wt CN_2, mean L-shaped CN_2, std_dev L-shaped CN_2, minimum L-shaped CN_2, maximum L-shaped CN_2, mean water-like CN_2, std_dev water-like CN_2, minimum water-like CN_2, maximum water-like CN_2, mean bent 120 degrees CN_2, std_dev bent 120 degrees CN_2, minimum bent 120 degrees CN_2, maximum bent 120 degrees CN_2, mean bent 150 degrees CN_2, std_dev bent 150 degrees CN_2, minimum bent 150 degrees CN_2, maximum bent 150 degrees CN_2, mean linear CN_2, std_dev linear CN_2, minimum linear CN_2, maximum linear CN_2
mean wt CN_3, std_dev wt CN_3, minimum wt CN_3, maximum wt CN_3, mean trigonal planar CN_3, std_dev trigonal planar CN_3, minimum trigonal planar CN_3, maximum trigonal planar CN_3, mean trigonal non-coplanar CN_3, std_dev trigonal non-coplanar CN_3, minimum trigonal non-coplanar CN_3, maximum trigonal non-coplanar CN_3, mean T-shaped CN_3, std_dev T-shaped CN_3, minimum T-shaped CN_3, maximum T-shaped CN_3
mean wt CN_4, std_dev wt CN_4, minimum wt CN_4, maximum wt CN_4, mean square co-planar CN_4, std_dev square co-planar CN_4, minimum square co-planar CN_4, maximum square co-planar CN_4, mean tetrahedral CN_4, std_dev tetrahedral CN_4, minimum tetrahedral CN_4, maximum tetrahedral CN_4, mean rectangular see-saw-like CN_4, std_dev rectangular see-saw-like CN_4, minimum rectangular see-saw-like CN_4, maximum rectangular see-saw-like CN_4, mean see-saw-like CN_4, std_dev see-saw-like CN_4, minimum see-saw-like CN_4, maximum see-saw-like CN_4, mean trigonal pyramidal CN_4, std_dev trigonal pyramidal CN_4, minimum trigonal pyramidal CN_4, maximum trigonal pyramidal CN_4
mean wt CN_5, std_dev wt CN_5, minimum wt CN_5, maximum wt CN_5, mean pentagonal planar CN_5, std_dev pentagonal planar CN_5, minimum pentagonal planar CN_5, maximum pentagonal planar CN_5, mean square pyramidal CN_5, std_dev square pyramidal CN_5, minimum square pyramidal CN_5, maximum square pyramidal CN_5, mean trigonal bipyramidal CN_5, std_dev trigonal bipyramidal CN_5, minimum trigonal bipyramidal CN_5, maximum trigonal bipyramidal CN_5
mean wt CN_6, std_dev wt CN_6, minimum wt CN_6, maximum wt CN_6, mean hexagonal planar CN_6, std_dev hexagonal planar CN_6, minimum hexagonal planar CN_6, maximum hexagonal planar CN_6, mean octahedral CN_6, std_dev octahedral CN_6, minimum octahedral CN_6, maximum octahedral CN_6, mean pentagonal pyramidal CN_6, std_dev pentagonal pyramidal CN_6, minimum pentagonal pyramidal CN_6, maximum pentagonal pyramidal CN_6
mean wt CN_7, std_dev wt CN_7, minimum wt CN_7, maximum wt CN_7, mean hexagonal pyramidal CN_7, std_dev hexagonal pyramidal CN_7, minimum hexagonal pyramidal CN_7, maximum hexagonal pyramidal CN_7, mean pentagonal bipyramidal CN_7, std_dev pentagonal bipyramidal CN_7, minimum pentagonal bipyramidal CN_7, maximum pentagonal bipyramidal CN_7
mean wt CN_8, std_dev wt CN_8, minimum wt CN_8, maximum wt CN_8, mean body-centered cubic CN_8, std_dev body-centered cubic CN_8, minimum body-centered cubic CN_8, maximum body-centered cubic CN_8, mean hexagonal bipyramidal CN_8, std_dev hexagonal bipyramidal CN_8, minimum hexagonal bipyramidal CN_8, maximum hexagonal bipyramidal CN_8
mean wt CN_9, std_dev wt CN_9, minimum wt CN_9, maximum wt CN_9, mean q2 CN_9, std_dev q2 CN_9, minimum q2 CN_9, maximum q2 CN_9, mean q4 CN_9, std_dev q4 CN_9, minimum q4 CN_9, maximum q4 CN_9, mean q6 CN_9, std_dev q6 CN_9, minimum q6 CN_9, maximum q6 CN_9
mean wt CN_10, std_dev wt CN_10, minimum wt CN_10, maximum wt CN_10, mean q2 CN_10, std_dev q2 CN_10, minimum q2 CN_10, maximum q2 CN_10, mean q4 CN_10, std_dev q4 CN_10, minimum q4 CN_10, maximum q4 CN_10, mean q6 CN_10, std_dev q6 CN_10, minimum q6 CN_10, maximum q6 CN_10
mean wt CN_11, std_dev wt CN_11, minimum wt CN_11, maximum wt CN_11, mean q2 CN_11, std_dev q2 CN_11, minimum q2 CN_11, maximum q2 CN_11, mean q4 CN_11, std_dev q4 CN_11, minimum q4 CN_11, maximum q4 CN_11, mean q6 CN_11, std_dev q6 CN_11, minimum q6 CN_11, maximum q6 CN_11
mean wt CN_12, std_dev wt CN_12, minimum wt CN_12, maximum wt CN_12, mean cuboctahedral CN_12, std_dev cuboctahedral CN_12, minimum cuboctahedral CN_12, maximum cuboctahedral CN_12, mean q2 CN_12, std_dev q2 CN_12, minimum q2 CN_12, maximum q2 CN_12, mean q4 CN_12, std_dev q4 CN_12, minimum q4 CN_12, maximum q4 CN_12, mean q6 CN_12, std_dev q6 CN_12, minimum q6 CN_12, maximum q6 CN_12
mean wt CN_13, std_dev wt CN_13, minimum wt CN_13, maximum wt CN_13
mean wt CN_14, std_dev wt CN_14, minimum wt CN_14, maximum wt CN_14
mean wt CN_15, std_dev wt CN_15, minimum wt CN_15, maximum wt CN_15
mean wt CN_16, std_dev wt CN_16, minimum wt CN_16, maximum wt CN_16
mean wt CN_17, std_dev wt CN_17, minimum wt CN_17, maximum wt CN_17
mean wt CN_18, std_dev wt CN_18, minimum wt CN_18, maximum wt CN_18
mean wt CN_19, std_dev wt CN_19, minimum wt CN_19, maximum wt CN_19
mean wt CN_20, std_dev wt CN_20, minimum wt CN_20, maximum wt CN_20
mean wt CN_21, std_dev wt CN_21, minimum wt CN_21, maximum wt CN_21
mean wt CN_22, std_dev wt CN_22, minimum wt CN_22, maximum wt CN_22
mean wt CN_23, std_dev wt CN_23, minimum wt CN_23, maximum wt CN_23
mean wt CN_24, std_dev wt CN_24, minimum wt CN_24, maximum wt CN_24
mean atomic_mass local diff, std_dev atomic_mass local diff, minimum atomic_mass local diff, maximum atomic_mass local diff
mean average_pair_atomic_distance, std_dev average_pair_atomic_distance, minimum average_pair_atomic_distance, maximum average_pair_atomic_distance
Gaussian center=0.0 width=0.1, Gaussian center=0.1 width=0.1, Gaussian center=0.2 width=0.1, ..., Gaussian center=9.9 width=0.1