
This script performs repeatable MEAMfit optimization using randomly selected VASP data files from the input folder, and evaluates the performance on a test set. Names of the randomly selected files are saved in a folder ‚Selected_files_RANDOM‘ for each iteration. The results of each iteration are appended to ‚output_file_random.txt‚, including details about: (1) the best optimization function, (2) energy variances in the fitted dataset, (3) force variances in the fitted dataset, (4) RMS error for energy in the fitted dataset, (5) RMS error for forces in the fitted dataset, (6) energy variances in the test dataset, (7) force variances in the test dataset, (8) RMS error for energy in the test dataset, (9) RMS error for forces in the test dataset, and (10) filename with the names of the randomly selected files. Also, the best found potential for each iteration is saved in the ‚Saved_best_params‚ folder.
sudo chmod +x Randomly_select.sh
./Randomly_select.sh
Note: If you encounter an error „-bash: ./Randomly_select.sh: /bin/bash^M: bad interpreter: No such file or directory“, it is an error due to line-ending issues, typically caused by editing a script on a Windows system and then running it on Linux system. Applying the following should solve this problem:
sed -i 's/\r//' Randomly_select.sh
source_dir="/home/lebedmi2/DATA/VASP_data/Si_xml/all_vasp_files"
target_dir="/home/lebedmi2/DATA/VASP_data/Si_xml/Fit_EAM"
target_test_dir="/home/lebedmi2/DATA/VASP_data/Si_xml/Test_set"
num_files=10 #number of files to randomly choose for the fit
num_iterations=50 #how many times to repeat the randomization of files and fitting
num_processors=8 #number of processors to use for MEAMfit
meamfit_binary=meamfit #name of the MEAMfit binary (the original one is MEAMfit.x)
Place this script in the main parent directory containing the 3 folders. Into the ‚source_dir‚ folder, copy all your *.xml files, from which you want to randomly select and fit the potential. Prepare the ‚settings‚ MEAMfit file in both the ‚target_dir‚ and ‚target_test_dir‚ folders.
Note: If you want to run this script parallely with different settings, you can place the ‚all_vasp_files‚ folder in a shared directory for all parallel runs. This way, you don’t need to copy the folder for each run into separate directories.
Ensure the ‚settings‚ file in the ‚target_test_dir‚ folder includes ‚POTFILEIN=potparas_best1‚. For example, ‚settings‚ files may look like this:
Example of the content of file ‚settings‚ in folder ‚target_dir‚:
TYPE=EAM
CUTOFF_MAX=4.4
NOPTFUNCSTORE=50
NTERMS=3
NTERMS_EMB=3
Example of the content of file ‚settings‚ in folder ‚target_dest_dir‚:
TYPE=EAM
CUTOFF_MAX=4.4
NOOPT=true
POTFILEIN=potparas_best1
NOPTFUNCSTORE=50
NTERMS=3
NTERMS_EMB=3
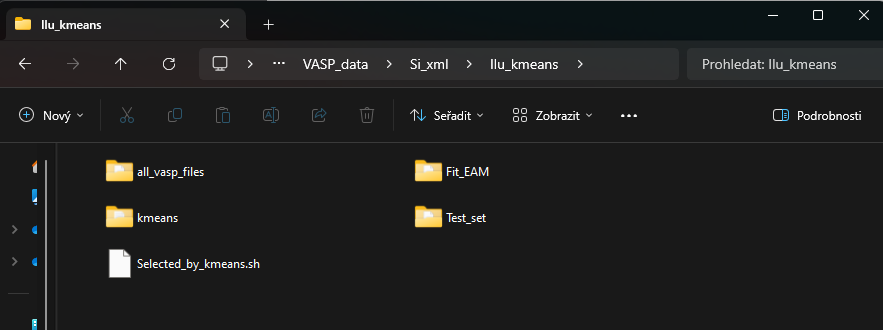
The created folders and their content may look like the following:
This script performs the same as the script before, but instead of randomly selecting the files that are used for the fitting, the files are selected as determined by k-means algorithm. The names of the k-means structures corresponding to the names of the *.xml files are saved in files within a given folder, from which the script reads them. The results are again listed in ‚output_file_random.txt‚, in the same fashion as the previous script.
sudo chmod +x Selected_by_kmeans.sh
./Selected_by_kmeans.sh
source_dir="/home/lebedmi2/DATA/VASP_data/Si_xml/all_vasp_files"
target_dir="/home/lebedmi2/DATA/VASP_data/Si_xml/Fit_EAM"
target_test_dir="/home/lebedmi2/DATA/VASP_data/Si_xml/Test_set"
kmeans="/home/lebedmi2/DATA/VASP_data/Si_xml/kmeans"
num_processors=8 #number of processors to use for MEAMfit
meamfit_binary=meamfit #name of the MEAMfit binary (the original one is MEAMfit.x)
Place this script in the main parent directory containing the 4 folders. Into the ‚source_dir‚ folder, copy all your *.xml files, from which the data will be selected and used for fitting. Prepare the ‚settings‚ MEAMfit file in both ‚target_dir‚ and ‚target_test_dir‚ folders. Into the ‚kmeans‚ folder, place the files determined by k-means algorithm which contain the names of the dataset to select for fitting. Ensure the ‚settings‚ file in the ‚target_test_dir‚ folder includes ‚POTFILEIN=potparas_best1‚. For example, ‚settings‚ files may look like this:
Example of the content of file ‚settings‚ in folder ‚target_dir‚:
TYPE=EAM
CUTOFF_MAX=4.4
NOPTFUNCSTORE=50
NTERMS=3
NTERMS_EMB=3
Example of the content of file ‚settings‚ in folder ‚target_dest_dir‚:
TYPE=EAM
CUTOFF_MAX=4.4
NOOPT=true
POTFILEIN=potparas_best1
NOPTFUNCSTORE=50
NTERMS=3
NTERMS_EMB=3
© 2026 Implant. Built using WordPress and the Materialis Theme